Program Arcade GamesWith Python And Pygame
Chapter 7: 列表入门
7.1 数据类型
到目前为止,书中介绍过4中数据的类型:
- 字符串(String)
- 整数(Integer)
- 浮点(Floating point)
- 布尔(Boolean)
Python可以同股使用type函数来显示一个值的类型。
这个type函数在编程时并不是十分有用, 但是可以很好地验证数据的真实类型。 在IDLE的交互端输入以下内容 (不要创建一个新的窗口并输入在一个程序里,这是行不通的。)
type(3)
type(3.145)
type("Hi there")
type(True)
|
Output:
>>> type(3)
<class 'int'>
>>> type(3.145)
<class 'float'>
>>> type("Hi there")
<class 'str'>
>>> type(True)
<class 'bool'>
|
也可以把type函数用在一个变量上来敲一敲它存储的数据是什么类型。
x = 3 type(x)
在这一章要介绍的两个新的数据类型是,新em>列表(Lists)和元组(Tuples). 试着在Python的交互端输入如下的命令,看看显示出了什么:
type( (2, 3, 4, 5) ) type( [2, 3, 4, 5] )
7.2 使用列表
你一定列过购物清单,计划列表,任务列表,但是你知道如何在计算机上创建一个列表吗?

在IDLE的命令行尝试以下的例子。 想创建一个列表并打印出来,可以这么做:
>>> x = [1,2] >>> print(x) [1, 2]
打印数组里的单独元素:
>>> print(x[0]) 1
这个表示元素位置的数字叫做索引. 请注意列表的起始位置是0。所以一个10个元素的列表并包含一个索引是[10]的元素。 索引只是从[0]一直到[9]。 创建一个10个元素的数组却不包含元素10的确很让人困惑,但是大多数计算机语言都是从0开始计数的。
想象有一个列表来表示一个盛若干冰块数的冰格,如图例所示7.2。 数值存储在每一个格子里,在冰格的侧面标记着每块冰块位置的数字,从0开始。
请记得, 在使用列表时有两组数字:位置和数值。 位置, 通常也表示成索引,是指在哪儿存数据。数值是真正存储在那个位置的内容。当使用列表的时候,务必确定你什么时候需要 位置,什么时候又需要数值。
获得某个位置的数值是很简单的,获得一个值的位置要困难许多。
第十五章专门会回答如何寻找一个特定的数值的位置。
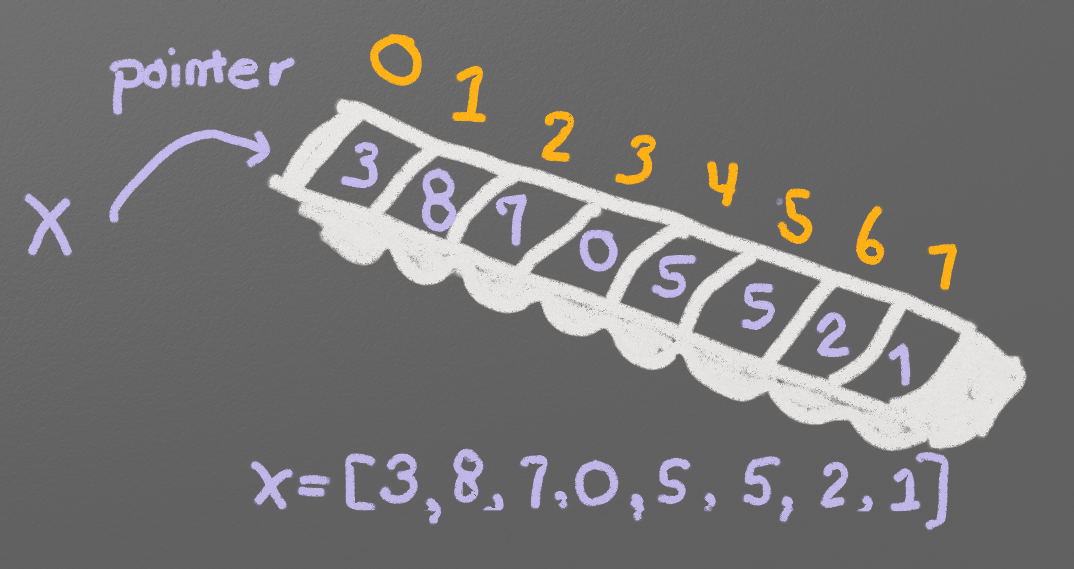
程序可以给一个列表里的单独元素赋予新的值。 在下面的例子中,在位置0(不是1)的第一个点被赋予了22。
>>> x[0] = 22 >>> print(x) [22, 2]
同时,程序也可以创建一个“元组”。这种数据类型和列表十分相似,但有两个不同点。第一,它是用圆括号而不是方括号创建的。 第二,一旦创建了就无法更改元组了。 请看下例:
>>> x = (1, 2)
>>> print(x)
(1, 2)
>>> print(x[0])
1
>>> x[0] = 22
Traceback (most recent call last):
File "<pyshell#18>", line 1, in <module>
x[0] = 22
TypeError: 'tuple' object does not support item assignment
>>>
从上面的输出代码可以看到,我们不能给元组中的元素设置一个新的值。 我们为什么需要这样的限制? 第一,计算机如果知道一个值不会被改变就可以运行地更快。 第二,有些列表我们并不想改变,比如用RGB列表表示的红色。 红色不应被改变,所以这里用元组来表示是更好的选择。
一个数组是由对象组成的列表。在计算机科学中数据结构非常重要。 在Python中的“列表”数据结构和一个传统的数组数据结构很相似。
7.3 列表的迭代
如果想把一个列表迭代一遍,比如打印出来,可以用两种for寻呼来做到。
第一种迭代的方法是用一个“for-each” loop。这种循环会取一个元素的集合,然后循环过每个元素。 它会先复制一个元素并存储在一个变量里进行处理。
命令的格式是这样的:
for 元素变量 in 列表名:
这是一些例子:
my_list = [101, 20, 10, 50, 60]
for item in my_list:
print(item)
|
Output:
101 20 10 50 60 |
程序也可以在列表里存储字符串:
my_list = ["Spoon", "Fork", "Knife"]
for item in my_list:
print(item)
|
Output:
Spoon Knife Fork |
列表甚至可以存储其他列表. 下面这个迭代了主列表,而不是子列表。
my_list = [ [2,3], [4,3], [6,7] ]
for item in my_list:
print(item)
|
Output:
[2,3] [4,3] [6,7] |
另一种迭代的方法是使用一个索引变量,然后直接访问列表而不是复制其中的元素。 要使用索引变量,程序会从0数到列表的长度。如果有十个元素,那么循环会从0数到9。
一个列表的长度可以使用len函数来找到。 结合range函数可以用来迭代整个循环。
my_list = [101, 20, 10, 50, 60]
for i in range(len(my_list)):
print(my_list[i])
|
Output:
101 20 10 50 60 |
这个方法稍微复杂一些,但是更加强大。 因为我们直接对着列表元素操作,而不是复制新的,所以列表可以被更改。 for-each循环并不允许修改原列表。
7.4 向列表里添加
使用append命令可以给列表(元组不能)添加新的元素。 例如:
my_list = [2, 4, 5, 6] print(my_list) my_list.append(9) print(my_list) |
Output:
[2, 4, 5, 6] [2, 4, 5, 6, 9] |
附注: 如果添加时的速度表现是一个担心考虑的因素,那就有必要理解列表是如何实现的。 例如,如果列表是用数组这种数据类型拉实现的来 那么在列表末尾添加一个元素就像给一打装满的鸡蛋盒里再添加一个鸡蛋。 这样就需要建立一个13个栏位的新的鸡蛋盒。 然后12个鸡蛋要搬过去。然后第13个鸡蛋再添加进去。 最后旧的鸡蛋盒被回收。 因为这些都发生在函数的幕后,程序员可能会忘记这些而让计算机做所有的事情。 所以如果简单地先告诉计算机创建一个足够栏位的鸡蛋盒会更加有效率。 幸运的是,Python并不是以数组类型来实现列表的。 但是对数据结构课还是要重视,明白背后的原理。
创建一个全新的列表,有必要先创建一个空白的列表然后再用append函数往里添加。下面这个例子就是更具用户的输入来创建列表的:
|
|
Output:
Enter an integer: 4 [4] Enter an integer: 5 [4, 5] Enter an integer: 3 [4, 5, 3] Enter an integer: 1 [4, 5, 3, 1] Enter an integer: 8 [4, 5, 3, 1, 8] |
如果想创建一个固定长度、里面数值都相等的数组,一个简单的技巧就如下例所示:
# 创建一个100个0构成的数组 my_list = [0] * 100
7.5 读一个列表求和或者修改
对一个数组求一个累计的和是一个常见的操作,可以如此完成:
# 复制数组到列表 my_list = [5,76,8,5,3,3,56,5,23] # 起始的和设为0 list_total = 0 # 从0循环至列表的长度 for i in range(len(my_list)): 加上元素0,元素1,元素2... list_total += my_list[i] # 打印结果 print(list_total)
相同地,我们也可以用一个for循环来迭代数组,而不是在一个范围内计数:
# 复制数组到列表 my_list = [5, 76, 8, 5, 3, 3, 56, 5, 23] # 起始的和设为0 list_total = 0 # 循环数组, 复制每个元素到一个变量元素 for item in my_list: # 加上每个变量 list_total += item # 打印结果 print(list_total)
数组中的数字也可以通过for熏画来更改:
# 复制数组到列表 my_list = [5, 76, 8, 5, 3, 3, 56, 5, 23] # 从0循环至列表的长度 for i in range(len(my_list)): # 对每个元素乘以2 my_list[i] = my_list[i] * 2 # 打印结果 print(my_list)
然而利用求和的版本2在对数值翻倍的操作并不能获得成功 为什么? 因为item是一个数组内元素的复制品。 下面的代码可以给复制品翻倍,而不是对原来的数组元素。
# 复制数组到列表 my_list = [5, 76, 8, 5, 3, 3, 56, 5, 23] # 循环myArray里的每一个元素 for item in my_list: # 这会对item翻倍, 但并不改变原数组 # 因为item只是一个复制品 item = item * 2 # 打印结果 print(my_list)
7.6 切割字符串
字符串实际上是由字符构成的列表。它们可以被视作由单个的字母组成的列表。用以下两种版本的x运行代码:
x = "这是一个示例字符串"
#x = "0123456789"
print("x=", x)
# 访问单个字符
print("x[0]=", x[0])
print("x[1]=", x[1])
# 从右端开始访问
print("x[-1]=", x[-1])
# 访问 0-5
print("x[:6]=", x[:6])
# 访问 6
print("x[6:]=", x[6:])
# 访问 6-8
print("x[6:9]=", x[6:9])
Python中的字符串可以进行一些数学的运算。 试着运行下面这段代码,看看Python砸做什么:
a = "Hi" b = "There" c = "!" print(a + b) print(a + b + c) print(3 * a) print(a * 3) print((a * 2) + (b * 2))
我们也可以获取字符串的长度。这种方法也可以获取各种类型数组的长度。
a = "Hi There" print(len(a)) b = [3, 4, 5, 6, 76, 4, 3, 3] print(len(b))
因为字符串是一个数组,我们就可可以像数组一样迭代其中每一个字符元素:
for character in "This is a test.":
print(character)
练习: 以下段代码开始下端
months = "JanFebMarAprMayJunJulAugSepOctNovDec"
n = int(input("Enter a month number: "))
打印用户输入的月份数字对应的三个字母的缩写 (先计算字符串的起始位置,然后用它拉打印出正确的子字符串。)
7.7 秘密代码
这段代码打印了出了一个字符串的每个字母:
plain_text = "This is a test. ABC abc"
for c in plain_text:
print(c, end=" ")
计算机实际上并不会把字母存储在内存中;存储的是一系列数字。 每个数字代表一个字母。计算机把数字转换成字母的系统叫Unicode。 完整名称是Universal Character Set Transformation Format 8-bit, 通常简称为UTF-8.
Unicode的表格用数字0-127涵盖了西方字母表。每个西方字符用内存中的一个字节表示。 其他字母表,比如西里尔字母,需要多个字节来表示美国字母。 下面是Unicode表格的一个部分:
| Value | Character | Value | Character | Value | Character | Value | Character |
| 40 | ( | 61 | = | 82 | R | 103 | g |
| 41 | ) | 62 | > | 83 | S | 104 | h |
| 42 | * | 63 | ? | 84 | T | 105 | i |
| 43 | + | 64 | @ | 85 | U | 106 | j |
| 44 | , | 65 | A | 86 | V | 107 | k |
| 45 | - | 66 | B | 87 | W | 108 | l |
| 46 | . | 67 | C | 88 | X | 109 | m |
| 47 | / | 68 | D | 89 | Y | 110 | n |
| 48 | 0 | 69 | E | 90 | Z | 111 | o |
| 49 | 1 | 70 | F | 91 | [ | 112 | p |
| 50 | 2 | 71 | G | 92 | \ | 113 | q |
| 51 | 3 | 72 | H | 93 | ] | 114 | r |
| 52 | 4 | 73 | I | 94 | ^ | 115 | s |
| 53 | 5 | 74 | J | 95 | _ | 116 | t |
| 54 | 6 | 75 | K | 96 | ` | 117 | u |
| 55 | 7 | 76 | L | 97 | a | 118 | v |
| 56 | 8 | 77 | M | 98 | b | 119 | w |
| 57 | 9 | 78 | N | 99 | c | 120 | x |
| 58 | : | 79 | O | 100 | d | 121 | y |
| 59 | ; | 80 | P | 101 | e | 122 | z |
| 60 | < | 81 | Q | 102 | f |
关于ASCII码(里面的西方字母用了和Unicode一样的数值)的更多信息请看:
http://en.wikipedia.org/wiki/ASCII
有一个视频介绍了Unicode的美丽之处, 请参看:
http://hackaday.com/2013/09/27/utf-8-the-most-elegant-hack
下面这组代码把之前例子的每个字母转换成了其在 UTF-8中的序号:
plain_text = "This is a test. ABC abc"
for c in plain_text:
print(ord(c), end=" ")
下面的程序取了每个UTF-8的值并加上了1。然后打印出了新的UTF-8值,并转换回了字母。
plain_text = "This is a test. ABC abc"
for c in plain_text:
x = ord(c)
x = x + 1
c2 = chr(x)
print(c2, end="")
下面的程序取了每个UTF-8的值并加上了1。然后打印出了新的UTF-8值,并转换回了字母。
# Sample Python/Pygame Programs
# Simpson College Computer Science
# http://programarcadegames.com/
# http://simpson.edu/computer-science/
# Explanation video: http://youtu.be/sxFIxD8Gd3A
plain_text = "This is a test. ABC abc"
encrypted_text = ""
for c in plain_text:
x = ord(c)
x = x + 1
c2 = chr(x)
encrypted_text = encrypted_text + c2
print(encrypted_text)
最后这段代码取了每个UTF-8的值并减去了1。然后打印出了新的UTF-8值,并转换回了字母。
用上段程序的输出结果来做输入,那这个程序可以看作先前例子的一个解码器。

# Sample Python/Pygame Programs
# Simpson College Computer Science
# http://programarcadegames.com/
# http://simpson.edu/computer-science/
# Explanation video: http://youtu.be/sxFIxD8Gd3A
encrypted_text = "Uijt!jt!b!uftu/!BCD!bcd"
plain_text = ""
for c in encrypted_text:
x = ord(c)
x = x - 1
c2 = chr(x)
plain_text = plain_text + c2
print(plain_text)
7.8 关联数组
Python并不限制于只使用数字来做数组的索引。我们也可以使用关联数组这种数据结构。 它是这样工作的:
# 创建一个空白的关联数组
# (注意使用了曲括号)
x = {}
# 添加一些内容进去
x["fred"] = 2
x["scooby"] = 8
x["wilma"] = 1
# 获取并打印其中一个元素
print(x["fred"])
在这门课中你并需要使用到关联数字,单色我觉得有必要指出这一点。
7.9 复习
7.9.1 选择题小测验
Click here for a multiple-choice quiz.
7.9.2 练习表
Click here for the chapter worksheet.
7.9.3 实验
Click here for the chapter lab.
English version by Paul Vincent Craven
Spanish version by Antonio Rodríguez Verdugo
Russian version by Vladimir Slav
Turkish version by Güray Yildirim
Portuguese version by Armando Marques Sobrinho and Tati Carvalho
Dutch version by Frank Waegeman
Hungarian version by Nagy Attila
Finnish version by Jouko Järvenpää
French version by Franco Rossi
Korean version by Kim Zeung-Il
Chinese version by Kai Lin